
我們說cross entropy可以用來衡量兩個概率分布(p和q)的差異,下圖推導的式子中
- p(y)是y_true|x的概率,服從Bernoulli distribution: p(y) = p ^ y * (1 - p) ^ (1 - y)
所以, p(y = 1) = p, p(y = 0) = 1 - p - q(y)是y_predict的概率,q(y = 1) = logistic function = h(x), q(y = 0) = 1 - h(x)
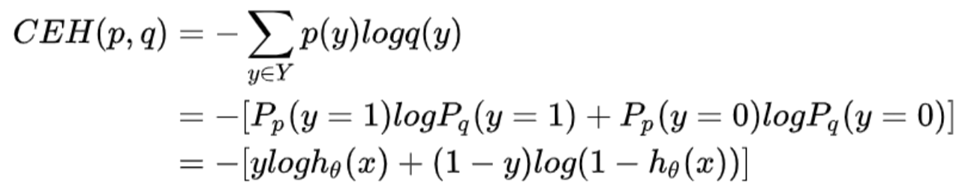
不理解從第二個等號到第三個等號,為什麼p(y = 1)是y,而不是p? 另外,我們想看Bernulli distribution和logistic function這兩個概率之間的差異,而y是y_true,y_true是value不是概率