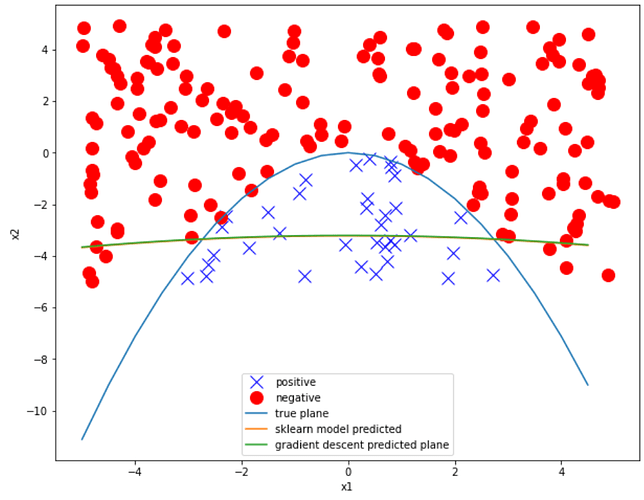
老師,能不能在notebook 3裡再加一個sklearn的方法?
我試著仿照notebook 2,加了下面的code:
regression_model = LogisticRegression()
regression_model.fit(X.reshape(-1, 2), Y.reshape(-1, 1))
print('Model intercept is: ', regression_model.intercept_[0])
print('Model coefficient is: ', regression_model.coef_[0])
y_predicted = regression_model.predict(X.reshape(-1, 2))
但是算出來的結果跟其他幾種方法差別很大
Model intercept is: -0.11462462872138378
Model coefficient is: [0.08227242 0.05527121]
不知道是model用錯了,還是畫圖錯了,畫圖用了下面的code
b_predicted = -(regression_model.coef_[0][0] * a + regression_model.intercept